
Your AI Results Are Inconsistent

You’ve watched it happen. A colleague drops an RFP into ChatGPT, asks for an executive summary, and gets back a draft that’s 80% there. It looks sharp and usable, maybe even good.
Two days later, you try the same thing. Same tool, same type of take. But you get back something that reads like it was written by someone who’s never seen a proposal in their life.
So we blame the tool. We assume ChatGPT had a bad day, or Claude doesn’t “get” proposals, or maybe you just need a better prompt template. Some secret formula perhaps.
That’s the wrong diagnosis, and acting on the wrong diagnosis is how capable professionals waste months getting mediocre returns from tools that should be accelerating them.
The Uncomfortable Truth About What’s Actually Happening
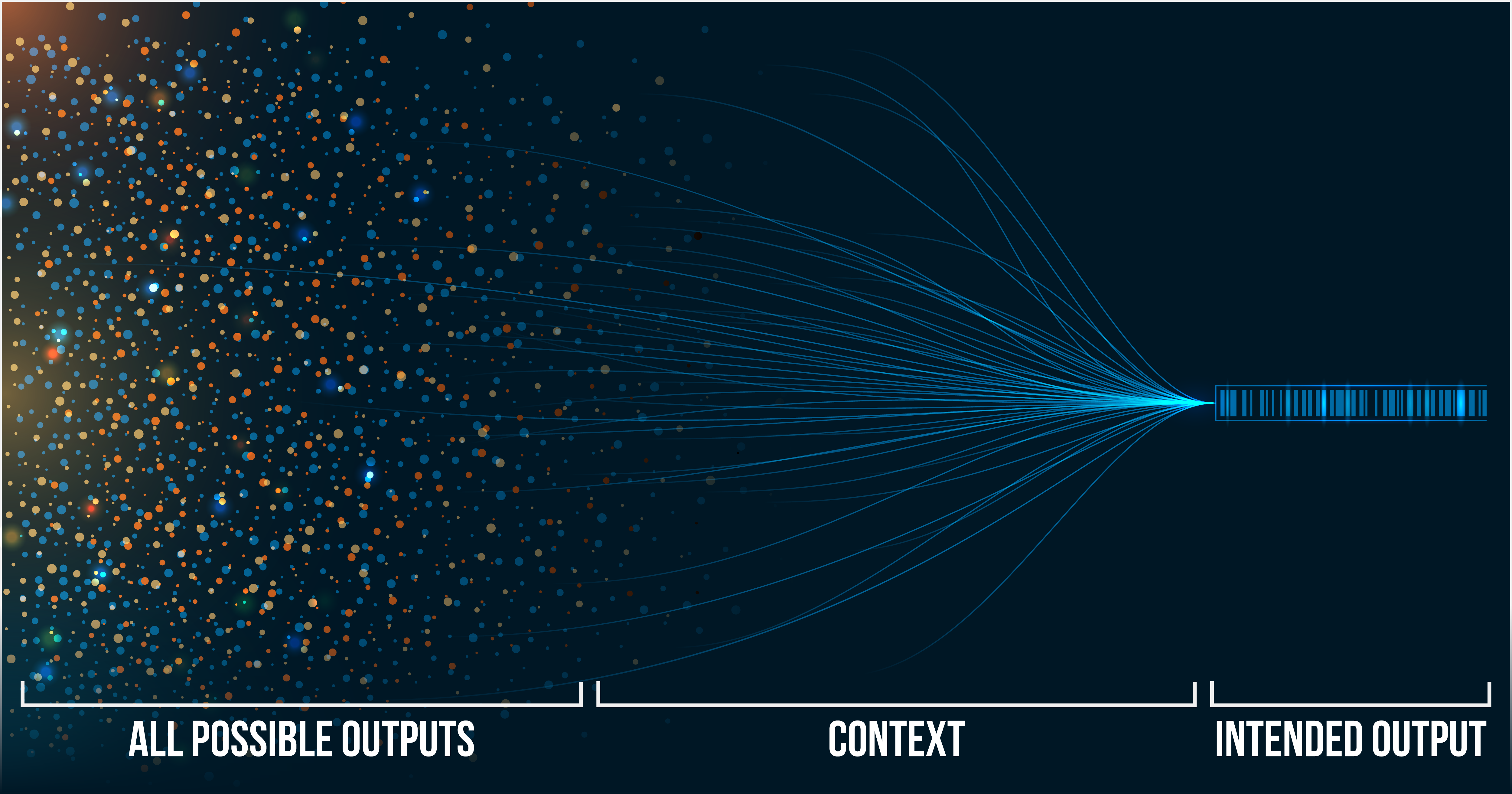
But AI doesn't have good days and bad days. It doesn't pull pre-written answers from some database. Every single response is generated fresh, and built from one thing: context.
Sure, there's some randomness baked in, but that randomness operates within boundaries. And you set those boundaries.
Thin context gives the model an open field. It could go anywhere. So it does, and the results feel generic because it IS generic. It’s the model’s best guess at what “good” looks like when it doesn’t know your opportunity, your evaluators, or your strategy.
Rich context builds a fence. The model still has room to work, but the output stays in your neighborhood. It reflects your reality instead of an averaged-out approximation of everyone’s.
Here’s the part most people don’t want to hear: when the output is bad, the input was incomplete. Not wrong, necessarily. Incomplete.
Why "Write Me an Executive Summary" is a Setup for Failure
Consider two prompts for the same task:
*Prompt A:* "Write an executive summary for this RFP."
*Prompt B:* "As a capture manager writing for GS-14 evaluators at HHS, draft an executive summary for this IDIQ opportunity. Our win themes are proven past performance on three comparable BPAs, a technical approach that reduces transition risk by 40%, and a cost structure that undercuts the incumbent by 12%. The goal is to position us as the lowest-risk choice before evaluators reach the technical volume.”
Prompt A tells the model almost nothing. It knows the format. It has a document to reference. Everything else is left to guesswork: who's writing, who's reading, what “good” looks like, what the competitive angle is, what success looks like, what methodology to follow. All of that is left to the model’s imagination which is actually just a composite of everything it’s ever read.
That’s not your proposal. That’s everybody else’s proposal.
Prompt B constrains the output across four dimensions: the writer's role, the audience's identity, the specific situation, and the strategic objective. The model isn't guessing. It’s solving a defined problem.
The difference in output quality between these two prompts is categorical.
The Four Perspectives Diagnostic
Next time you get a disappointing result from AI, run this check. Ask yourself which of these perspectives you actually provided:
1. Self. Did you tell AI your role, expertise, constraints, or level of authority? (“As a proposal manager on a re-compete where we’re the incumbent...”)
2. Audience. Did you specify who receives, evaluates, or acts on this output? Not just the customer, but the actual evaluators. Their grade level, the criteria they’re scoring against, their roadmap for success. ("...for GS-14 evaluators who will score against Section M criteria...")
3. Situation. Did you anchor this model in THIS opportunity? Not proposals in general. The contract vehicle, your win themes, the competitive landscape, the timeline. (“...on a $40M IDIQ recompete where the incumbent is underperforming on delivery timelines...”)
4. Purpose. Did you tell the model what this output needs to accomplish (including what it’s for)? (“...to position us as the lowest-risk transition partner before evaluators reach the management volume.”)
Most professionals provide one or two of these perspectives when prompting AI. Then they wonder why the output reads like it was written by someone who doesn’t work here.
It does. You just didn’t tell the model what it should do.
What Consistent Performers Do Differently
Professionals who get reliably good results from AI share one pattern: they provide more context than feels necessary. Where most people write one sentence, they write a paragraph. Where most people assume AI knows what "good" looks like, they describe it explicitly.
More signal. More context.
It's about providing enough information so that the model is unable to fill gaps with wrong assumptions.
Think about how you’d delegate to a new team member on their first day. You wouldn’t say “write me a summary of this RFP.” You’d say If you say “write a summary for the capture team that highlights requirements where we have competitive advantage, formatted like the summary I did for the DOL opportunity last month, focusing on Sections C and L.”
Same principle. AI can hold more context than any person on your team, but that context needs to come from you.

One Shift That Can Change Everything
Before your next AI interaction, try this: write down who the output is for before you write the prompt.
Not the format. Not the topic. The audience.
This single move forces a fundamental shift. You stop treating AI like a search engine that owes you an answer and start treating it like a collaborator that needs a briefing. Instead of "give me an executive summary," you're thinking "give me an executive summary that will convince skeptical evaluators we're the lowest-risk option on a contract where the incumbent has been stumbling."
That shift changes what you include. What you include changes your output. And suddenly the tool works the way you hoped it would the first time.
From Random Wins to Repeatable Advantage
Inconsistent AI results feel frustrating because they look random. But they're not. They're the predictable consequence of incomplete context. Every time.
Provide more perspectives, and you narrow the possibilities. Narrow the possibilities, and the output converges on something useful.
The question is whether you'll figure that out through 6 months of trial and error, or learn it in a single day.
Shipley’s AI 2026 Workshop gives proposal professionals the structured prompting techniques, multi-tool workflows, and strategic integration approaches that turn inconsistent experiments into a repeatable competitive edge. You’ll work through real proposal scenarios, see live demonstrations across tools, and walk out with a Credly badge and credit toward Shipley certification.
Register for Shipley AI 2026 and stop hoping the next prompt will be the one that works.
Let us Help You Win
Whether you need training or consulting support to facilitate your next win, click one of the options below and let's get started.
